Writing a search engine is hard. When confronted with the endless complexities of language, it is usually best to use code written by other, presumably smarter, people. For whatever reason, I was recently forced to implement my own search engine. Although this might have been accomplished with sufficient guesswork, I decided to try and derive an appropriate algorithm with math! I’ve documented my approach here if anyone else ever finds themselves in a similar situation.
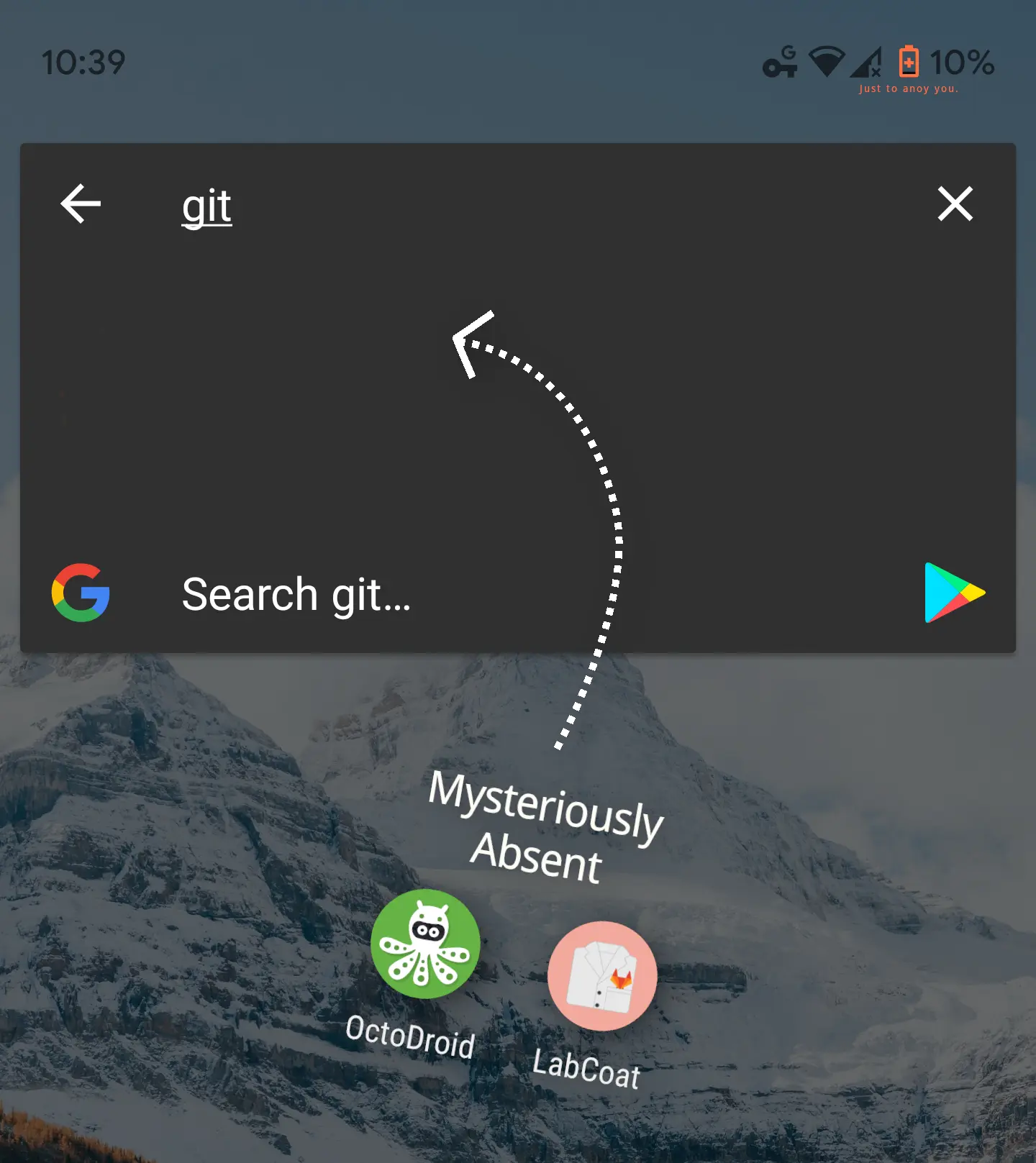
Before we begin, we need some data to search. I am endlessly annoyed that searching “git” on my phone doesn’t bring up either the “OctoDroid” or “LabCoat” apps, so let’s reinvent my app drawer.
Constructing a Model
I use my app drawer’s search bar when I want to find and open a specific app that is otherwise buried in a sea of little circle icons. So the drawer should really be trying to guess what app I want to open. Apps that are more likely should come first and apps that are not at all likely should be left out entirely.
Before I type a single letter, our search algorithm can already make some reasonable guesses. Most of the time I am just going to select Firefox, Google Maps, or Reddit. Those apps should start out at the top of the drawer. Only once I type “g” should git-related apps start moving up.
Conditional Probability
The probability that I select an app , before typing anything, is called the “prior probability” and written . Once we have some more evidence of my intentions (in the form of me typing some search query ), we want to use use the probability of “ given that evidence” which is written as . This is called conditional probability. So, how do we calculate conditional probability? In this case, we will use a little recipe called Bayes’ Rule, which says that:
We already know how to estimate (the prior probability that I am looking for no matter the query). Simply track how often I open each app.
But what is ? That’s the probability of me typing some query no matter the app I’m looking for and it is a little tricky to estimate. Thankfully, we can come back to it later since it isn’t needed to simply rank apps relative to each other. depends on the query only and so effects the probability of for each app equally.
So all we need now is ! What is ? Well, if is the probability of me looking for given I have typed , then must be the probability of me typing given I am looking for . To calculate this probability, let’s think through a hypothetical sequence of events:
- I am looking for “LabCoat”
- Since “LabCoat” is an app for managing git repositories, I think “git”
- I start by typing the letters “gi”
There are now a bunch more probabilities we need to deal with:
Conceptually, typing “gi” is evidence that I am thinking “git” which in turn is evidence that I am looking for LabCoat. By applying some rules of conditional probability to Bayes’ Rule above (which is left as an exercise for sufficiently bored readers), we get:
In human-speak, this equation says:
“The likelihood that I am looking for some app is proportional to the similarity of the query to a keyword times the relevance of that keyword to the app summed over all relevant keywords.”
The term is fairly easy. It is just a metric for how relevant is as a keyword for . If LabCoat has keywords of equal weight, then . If some keyword is stronger, then we can give it a little more probability and the others a little less.
But it is still a unclear how we should estimate . I did this by borrowing the concept of an “edit” which is some alteration from one item of text to another.
Edit Distance
Let’s suppose I think the word “firefox” but then type “frefo”. To a human it is pretty easy to guess what happened, but how can a computer guess? If you remember your college computer science courses you may be screaming “use the the Levenshtein distance!” at your screen. However, the goal of this blog post is to derive a search algorithm from first principals. So if we want to use the the Levenshtein distance (or a similar edit-distance metric), we will have to justify it mathematically.
Let’s define as a sequence of edits which is made of individual alterations . The probability is simply the likelihood of all occurring. Some alteration might be very likely if it is just me leaving some letters off the end of a word (afte al, typin is so borin) but less likely if it is something like replacing “i” with “q”.
But how does relate to ? Let’s define which is the probability of me typing when I meant to type but made edits . If does indeed change into , then the probability is 100%. When those edits are applied to that keyword it will always result in the query. Otherwise the probability is 0.
Now from the rules of probability, we can get:
See how the term just acts like a filter, so that we sum only the probabilities of all edits that change into ? For example, to calculate the probability that we type “firefox” as “frefo”, we sum the probabilities of:
- Deleting the “i” and the “x”.
- Deleting “ox” and replacing “iref” with “refo”.
- Inserting an “f”, deleting “fo”, and deleting “x”.
- …
But conceptually this equation calculates a sum, not the minimum, which prevents us from using the traditional algorithm for edit distance. And these aren’t really distances (1 edit, 2 edits, etc) at all but probabilities (1%, 30%, etc). What is going on?
Negative Log
Let’s take a break from math and think about how we might implement this algorithm so far (an exercise I may attempt in a later post). Throughout this process we keep multiplying small probabilities together to get even smaller probabilities. Like, what is the chance of replacing “iref” with “refo”, out of all the mistakes I could possibly make? Even randomly forgetting an “i” is pretty unlikely. And with all the apps on my phone, how often do I open an app to, say, change my wallpaper? We are running into dangerous floating-point-precision territory here. The probabilities of making specific queries could be on the order of or less for anything but a perfect match.
Maybe we should be using exponential notation? We could take the negative log of each probability. So instead of saying we will say . Because of the precision benefits, using log probability is a pretty common practice in computer science. The notation of instead of comes from information theory, where the log probability is called “information content” or “surprise”. Information theorists would also tell us that if we use base 2, our log probabilities will be in units of bits! But what does all that do to our math?
Cool! Products become sums and we are one step closer to using the edit distance. And what happens to sums like ? Unfortunately there is no simple way to do the log of a summation. But what are the terms in that summation? The probabilities of different, increasingly convoluted edits. As the edits get more convoluted they require exponentially more unlikely alterations. So most of the edits in that sum are massively less probable than the most probable edit and contribute little to the total. In fact, the log of a sum is used in machine learning as a soft approximation of maximum. Thus, the log of this sum is well approximated by the log probability of the maximally probable edit (the one with the lowest log probability):
Voilà, is well approximated by the minimum edit distance between and ! This approximation works well for other sums in our algorithm. So long as we assume each query is much closer to one keyword than to the others, we now have:
And as discussed above, we can leave out the term if all we need is a relative score. At last, we have a mathematically derived scoring function for our search algorithm: